

#36 Increased Performance! 🔋
This week, our Serverless expert is AWS Community Builder Tycko Franklin, our spotlight falls on AWS Community Builder Lee Priest, we look at the latest AWS service releases, news, articles, & more!


Welcome
In last week’s issue, our serverless expert was AWS Community Builder Elena van Engelen-Maslova, and our spotlight fell on AWS Community Builder Alessandro Volpicella!
This week, our serverless expert is AWS Community Builder Tycko Franklin, our spotlight falls on AWS Community Builder Lee Priest, we look at the latest AWS service releases, blog posts, hints and tips, news and more!
This week’s newsletter is sponsored by Leighton.
A Glimpse into My Week 🎤
This week, I published two separate articles which I had created a while back and didn’t get around to publishing. The first is Amazon Cognito M2M Token Caching for Cost Optimisation & Performance. This article covers how we can cache access tokens using a serverless proxy to ensure we don’t hit performance limits and to reduce the costs significantly!

The second article was a short one called Amazon Bedrock AI Model Cross-Region Inference. This covers the limitations of using Amazon Bedrock and how we can mitigate them using cross-region inference.

📰 Articles that caught the eye
Here are some stand-out articles I read during the week in the World of Serverless!

⭐ My favourite this week was the article by Zied Ben Tahar covering RAG with AppSync Events and Amazon Bedrock!
Zied Ben Tahar covers “Serverless RAG Chat with AppSync Events and Bedrock Knowledge Bases“.
Ran Isenberg discusses “Build Serverless WebSockets with AWS AppSync Events and Powertools for AWS Lambda“.
Vadym Kazulkin discusses “Quarkus 3 application on AWS Lambda- Part 1 Introduction to the sample application and first Lambda performance measurements“.
Thomas Aribart covers “Building a multi-region Serverless API with the AWS CDK, Lambda, and DynamoDB“.
Jimmy Dahlqvist has a great second article on “PEP and PDP for Secure Authorization with AVP and ABAC“.
Marcos Henrique has a great article on “The Gift of Reasoning: Enhancing Amazon Nova Lite with VoltAgent for Character Quirks“.
🎓 Ask the Expert
Each week, I ask a different serverless expert the same three questions to get their personal insights - this week, we have AWS Community Builder Tycko Franklin:

Opinions are the author’s and do not express the views of their employer.
1. What is one common mistake you see teams making when implementing serverless solutions, and how can they avoid it?
Seeing the previous "Ask the Expert" answers, it's hard to follow up on all that amazing content by smart people without repeating topics. I believe this mistake was brought up before, but maybe not in the same way.
The most common mistake I see when implementing serverless solutions is not embracing and learning the security features, benefits, configurations, and gotchas that serverless (highly managed) services bring.
Note: I will be using AWS terminology, but these ideas apply to all cloud providers offering serverless solutions.
One issue is that teams often don’t adopt the serverless security mindset and take advantage of shared security models. When I'm building an application and running it in production, I want my application to be as secure as possible (who wouldn't?).
When things go wrong in the security world, such as a zero day exploit, I want my applications' vulnerabilities addressed as soon as possible. When using serverless solutions, a lot of security concerns are automatically handled for me by AWS, a trillion-dollar company, that has a vested interest in keeping their offerings safe and secure.
The same holds true for serverless in Azure or GCP (both also trillion-dollar companies). If something needs patching, and it's on AWS' end of the shared security model, I have confidence it will be addressed quickly, as they have massive amounts of resources and a huge talent pool of engineers to get a fix in place as soon as possible. It is highly likely that cloud providers will find and address these issues before they are even known by many applications teams out there.
Adopting a serverless-first mindset helps to keep applications' attack surface smaller, and the number of potential attack vectors lower, and allows us to concentrate on other areas. The mistake comes from concentrating on security issues that affect more traditional resources, such as VMs or physical machines, where a lot more of the security gets shifted to the application team and the team can't take advantage of offloading a lot of security work. I see people spending effort in security areas that just aren't needed when working with serverless. An example is treating S3 file keys like traditional file system paths where directory traversal is a real issue but with S3, it would just make the key longer and be obvious proof someone tried to hack the system. This is because the key is just a key as a whole, not a way to traverse file systems.
Second, following up from the positive, there is also the negative: it can be super easy to get a false sense of security in the shared security model. This can easily lead to misconfigured security in a way that negates the cloud provider's side of the shared security model.
The cloud provider could have set up the most secure service in the world, but if it's configured to let anyone access it and change it, that security goes right out the window. It is a shared security model, so the application team does need to do their part and not leave everything up to AWS.
If we deploy an S3 bucket with open access and no restrictions, it’s up to any malicious actor what kind of damage they want to cause in that S3 bucket. Another area on this: IAM Roles for compute (Lambda, Fargate) are easily misconfigured and left vulnerable. For people coming into serverless, it can be daunting to set up IAM Role permissions correctly, and they can easily get frustrated and give the Role admin access to the account. All it takes is one malicious package in Python or Node.js, or any other language, and a malicious actor has admin access to your account.
Then there is runtime, if somehow a malicious actor got a vulnerability through to your compute layer, having administrator access could be devastating. Proper configuration of security is vital to prevent this. The more granular you make permissions, the more secure your application will be; however, there is a balance between getting too granular and slowing down development by too much, and not getting granular enough and leaving your application open to attack (but development is quick).
The neat part is that it can be a journey of iterative improvements. If an application team does grant administrator access to a role, that can be mitigated in a series of steps; Full access to DynamoDB is better than Administrator access to the entire account. Limiting the role policies to specific services can move the needle, and drastically reduce the attack surface. Once role policies have been isolated to services, you can go service by service and fine-tune them down from full access to access for specific resources in specific ways e.g. Read only on a specific DynamoDB table. This allows you to get down to only allowing IAM permissions you need for your workload. Learning IAM and how to isolate down to specific resources for a given workload is a valuable, continually rewarding skill for projects over time and helps remove some of the friction of staying secure while being able to quickly develop awesome solutions.
2. Which serverless tool or service are you most excited about right now, and why?
This one is really tough. My hammer (where everything is now a nail) is definitely DynamoDB. Having a solution that scales more than I could need, and does so with decent costs, is something I reach for again and again.
However, I would instead of concentrating on one service, mention that what I'm most excited about these days is the integration of many databases/services that consume the same data but store and expose it differently to meet various workload needs.
I'll model data in NoSQL for quick, (easily) scalable, and inexpensive storage for frontend facing APIs for quick applications that handle concurrent use without getting bogged down. I'll then take that same data and ingest it into other database types. I love the DynamoDB -> Athena workflow, where I can take a single table design in DynamoDB, and set up Athena to query on an export from it.
Generally, the adhoc queries that are needed don't need to be completed quickly or show in a UI, so services like Athena work amazingly. I love the idea of serverless, even cloud in general, that you can build an amazing workflow and keep extending it with services, often without affecting the previous work.
Serverless services act as building blocks that you can add, connect, and use without many issues normally. Need to represent your data as a graph? Keep the current setup, and sync the data up to a graph database. The idea that there isn't a silver bullet database service, but that you can just add a specific database type to the mix that will solve the problem, is just amazing in my mind and opens up so many possibilities.
3. What is your favourite trick or tip when working with serverless that the readers may find interesting?
I use AWS CDK for my AWS Serverless infrastructure as code, and my favorite trick is that instead of prop drilling or a spiderweb of imports, I use a centralized resource register (e.g., one per resource type: Roles, Lambdas, etc.) for defining resources in one place, and using them in another.
This allows me to make the CDK stacks very modular and organised with fewer lines of code per file. Using the centralised register, I can also prevent duplicate named resources as I define them, while also validating that I have defined them when I reference them in another place.
Order does matter in this case when defining the resources, but it has served me well again and again. As an example, when I create a lambda, I register it with addLambda(resourceName, lambda), so if I need to use it elsewhere — say, in a Step Function, I can do getLambda(resourceName) and it will grab it (even if it's on the other side of the code base). If the resourceName was not registered before, it will give an error. This keeps the code lean and simple, but allows the codebase to be organised in a way that makes it easy to find things and not get lost in the codebase. I'm planning a blog post on this, so keep an eye out!
✅ Bonus tip: join the hashtag#believeinsls discord! There is a community there to answer any questions you may have without getting overzealous on serverless or without judgment! Check it out!
💡 Hints & Tips
Each week, I share quick hints or tips based on things I notice in day-to-day engineering life.
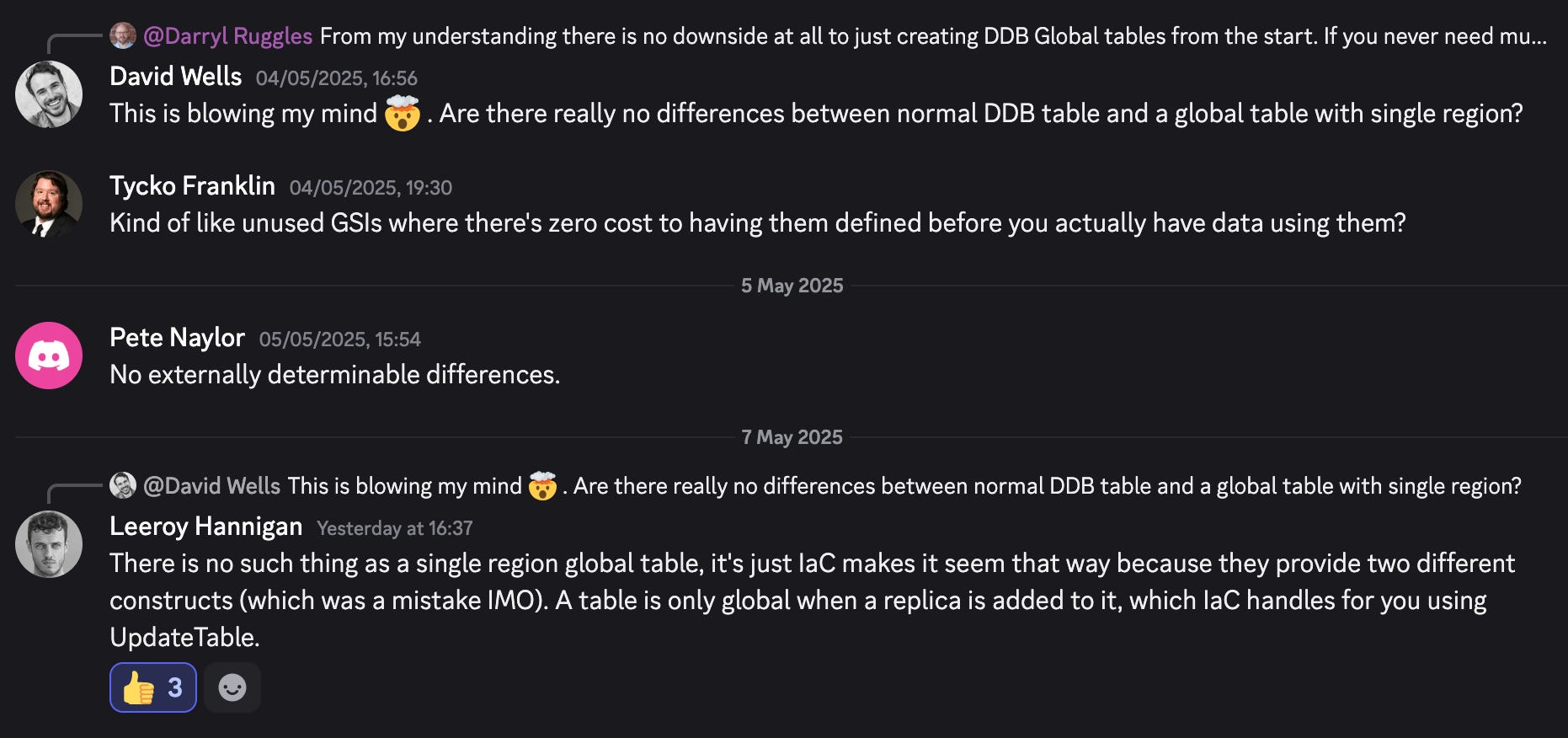
⭐ [Tip 1] Amazon DynamoDB Global Tables
I was today years old when I found out that DynamoDB Global Tables do not differ technically from normal Tables under the hood, meaning that you can safely use Global Tables all of the time to future-proof your solutions, without having to do rework in the future if you need to move from normal tables to Global ones!
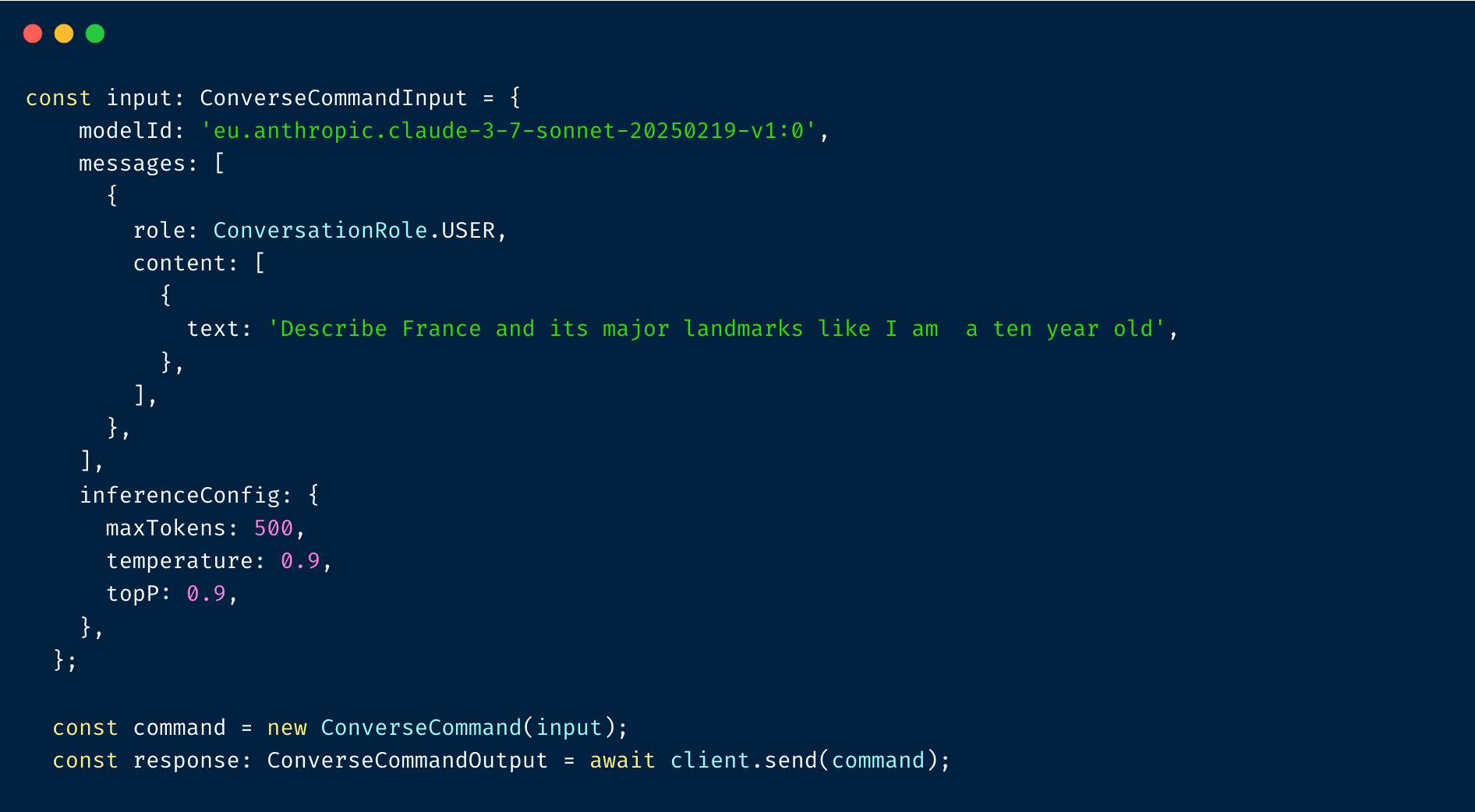
⭐ [Tip 2] Amazon Bedrock Cross-Region Inference
Have you used Amazon Bedrock in your solutions but hit regional limits? You can limit this from happening by using cross-region inference, which will route your model requests to other regions when a particular region is rate-limiting customers. The example below shows how we can use an inference modelId rather than a regional one:
⭐ [Tip 3] Typescript template literal strings!
This one came from Matt Peacock on LinkedIn, where he shows how you can use a template literal string to make sure your “Authorization” headers are correctly formatted. Here is an example below, which throws an error if the value does not start with “Bearer”:

🚀 New Releases
Here are the latest and most interesting releases this week in the AWS World:
⭐ This week, was fairly quiet in all honesty, but my favourite was probably the updates to CodePipeline.
Amazon CloudWatch RUM adds support for Interaction to Next Paint (INP) Web Vital.
Amazon DocumentDB (with MongoDB compatibility) is now available in the AWS Europe (Stockholm) Region.
Amazon Route 53 Resolver Query Logging now available in two new AWS Regions.
Amazon S3 Tables are now available in eleven additional AWS Regions.
Amazon CloudWatch Network Monitoring adds multi-account support for flow monitors.
Amazon Verified Permissions now supports policy store tagging.
Amazon SES now supports IPv6 when calling SES outbound endpoints.
Amazon Bedrock Data Automation now supports extraction of custom insights from audio.
The Amazon Q Developer integration in GitHub (preview) is now available.
AWS CodePipeline now supports Secrets Manager and more configurations in Commands action.
Amazon MSK enables seamless certificate renewals on MSK Provisioned clusters.
Amazon ECS introduces 1-click rollbacks for service deployments.
🔥 Tip: Check out https://aws-news.com/ for the very latest up-to-date serverless releases as they happen, created by the talented AWS Serverless Hero Luc van Donkersgoed.
👷🏻 Tools & Frameworks
Check out the latest open-source frameworks, news, and tool updates from the past week.
LocalStack 4.4 - This release brings a new Amazon Verified Permissions provider, a LocalStack-native RDS provider, a container-based Glue job executor, and many other enhancements across services, such as Step Functions, IAM, KMS, EMR Serverless, CloudFront Lambda@Edge, and Application Auto Scaling.
Node.js v24.0.0 - This release brings several significant updates, including the upgrade of the V8 JavaScript engine to version 13.6 and npm to version 11.
sample-serverless-mcp-servers - This repo contains a collection of sample implementations of MCP Servers.
💡 DynamoDB Tip of the Week

Each week we have a quick DynamoDB tip from our resident DynamoDB expert, Uriel Bitton.
💡 “Use key overloading to satisfy multiple access patterns with your base table or one GSI”
You can design partition and sort keys in a way that supports various query patterns. This avoids creating multiple GSIs and helps you keep costs and complexity low.
Further reading: https://www.linkedin.com/pulse/overloading-your-primary-keys-highly-efficient-queries-uriel-bitton-e4v1f/
✖️ Social of the Week
This week’s social is on Twitter by DHH, discussing how they are moving away from S3:

Massive kudos to AWS for this from a customer obsession perspective (they are not small amounts!). What are your thoughts on moving away from cloud providers to your own data centre?
🎙️ YouTube & Podcasts
Here are some of my favourite videos and podcasts this week.

⭐ My favourite video this week is by Luciano asking if App Runner is better than Fargate, or not?
James Eastham has a fantastic video on “Why Your Lambda Functions Need a Structural Makeover”.
Kris Jenkins discusses the “Side-Effects Are The Complexity Iceberg“.
Luca Mezzalira covers “Are conferences STILL worth it in 2025?“.
Brooklyn Zelenka & Julian Wood discuss Beyond the Cloud: The Local-First Software Revolution.
Allen Helton and Andres Moreno did a great livestream session named “Building an agent-ready API from scratch. No humans allowed“
“Is App Runner better than Fargate?“ by Luciano Mammino on AWS Bites.
Weekly Case Study 🔍
This week’s case study comes from the BMW Group:

BMW migrated its customer messaging system to Amazon Aurora Serverless v2 on AWS to handle over 10 million messages per hour, achieving 99.99% uptime, reduced operational costs, and automated scalability without over-provisioning.
By using Aurora’s on-demand scaling and zero-downtime patching, BMW eliminated outages, improved global performance, and freed up engineering teams to focus on innovation. The shift to a serverless architecture enabled BMW to unify its 1,300 microservices across international hubs and continues to support their goal of building highly scalable, cost-efficient cloud systems.
🗣️ Inspirational Quotes and Thoughts
This week’s inspirational quote comes from Professor Meir "Manny" Lehman:

“Continuing change is necessary; a system that is used will undergo continual change or become progressively less useful.”
- Meir "Manny" Lehman
This is one of the eight laws by Professor Lehman, which specifically means no architecture or solution stays static. Business needs, traffic patterns, security requirements, etc, all change. A system needs to adapt to this change, or risk rotting and becoming less useful for its users. Many companies see a solution as a one-and-done though, where it is delivered and they move on to the next; and this is a massive risk to those companies on many fronts, one of which is security.
What are your thoughts and experiences with this quote? Feel free to leave a comment below.
🗳️ Poll of the Week
In last week’s poll, we asked the question “Are you actively embedding AI into your Serverless applications?”.
Interestingly, 43% said yes, and 57% said no.
It’s an interesting one, as there is a lot of hype around generative AI and coding assistance at the moment (especially around Vibe coding!), and I am seeing fewer and fewer people talking about AI in their products with actual, meaningful use cases.
This week, we ask the question, “Are you using Cloudflare’s compute, database, storage, media and AI services?”. Have you gone all in on them, or perhaps just dabbling with, or even maybe not used any or not aware of them?
Feel free to leave a comment below on why you chose your answer and your experiences!
📅 Serverless Events
The following serverless events are upcoming, so mark your calendars.
🎟️ To note, CFP is currently open for the AWS North Community Conference, which I am helping organise, and we also have opportunities for lightning talks throughout the day. Go check it out!

Other fantastic events happening soon:
ACD Switzerland - 22nd May 2025
ACD Bengaluru - 23rd May 2025
ACD Midwest - 5th June 2025
ACD Australia - 15th August 2025
ACD Adria - 5th Sept 2025
AWS Community Day Baltic - 10th Sept 2025
ACD Aotearoa - 18th Sept 2025
ACD Poland - 18th Sept 2025
ACD Portugal - 27th Sept 2025
ACD DACH - 7th Oct 2025
AWS North Community Conference - 16th Oct 2025
Do you have any upcoming events that you want to highlight? Message me below!
⭐ Spotlight
This week’s spotlight falls on AWS Community Builder Lee Priest!

Lee is a Senior Engineer at the Lego Group, an AWS Community Builder, speaker, blogger, and open-source contributor - all very much in the AWS and Serverless space! I know Lee is working on some cool open-source projects as we speak, so definitely stay tuned and go connect with him on his social media channels!
Thank you for all you do for our wonderful Serverless community!
Thank you for reading the latest Serverless Advocate Newsletter!
If you want to find out a little more about me, please have a look at:
https://www.serverlessadvocate.com/
See you next time,
Lee

I've come to appreciate DHH's choice to leave the cloud. Obviously I'm a big serverless fan myself, and would build applications in a different way than they do. But if you're running on a big Rails+MySQL monolith, and you can leverage tools like Kamal for deployment (which I've used for some side projects and it's truly delightful), then I can really see the attraction of running on your own servers. They can save a lot of money that way, and there's not much value that the cloud can add for an application like that.